
VOCR - Video Optical Character Recognition
Liens clés
Introduction
Un OCR (Optical Character Recognition) est un logiciel qui permet d'extraire du texte depuis une image. EasyOCR est un OCR prêt à l'emploi utilisant OpenCV (Open Source Computer Vision), une bibliothèque logicielle libre destinée au traitement d'images en temps réel.
Nous allons voir ici comment utiliser EasyOCR et OpenCV pour construire un outil en python permettant de suivre l'évolution de données textuels sur une vidéo ou un stream vidéo.
Objectif
Prenons la vidéo suivante :

L'objectif ici est d'extraire les informations textuels de cette vidéo, et plus spécifiquement ici, le texte central (nous nous contenterons ici du texte, cf VOCR pour plus d'informations) :
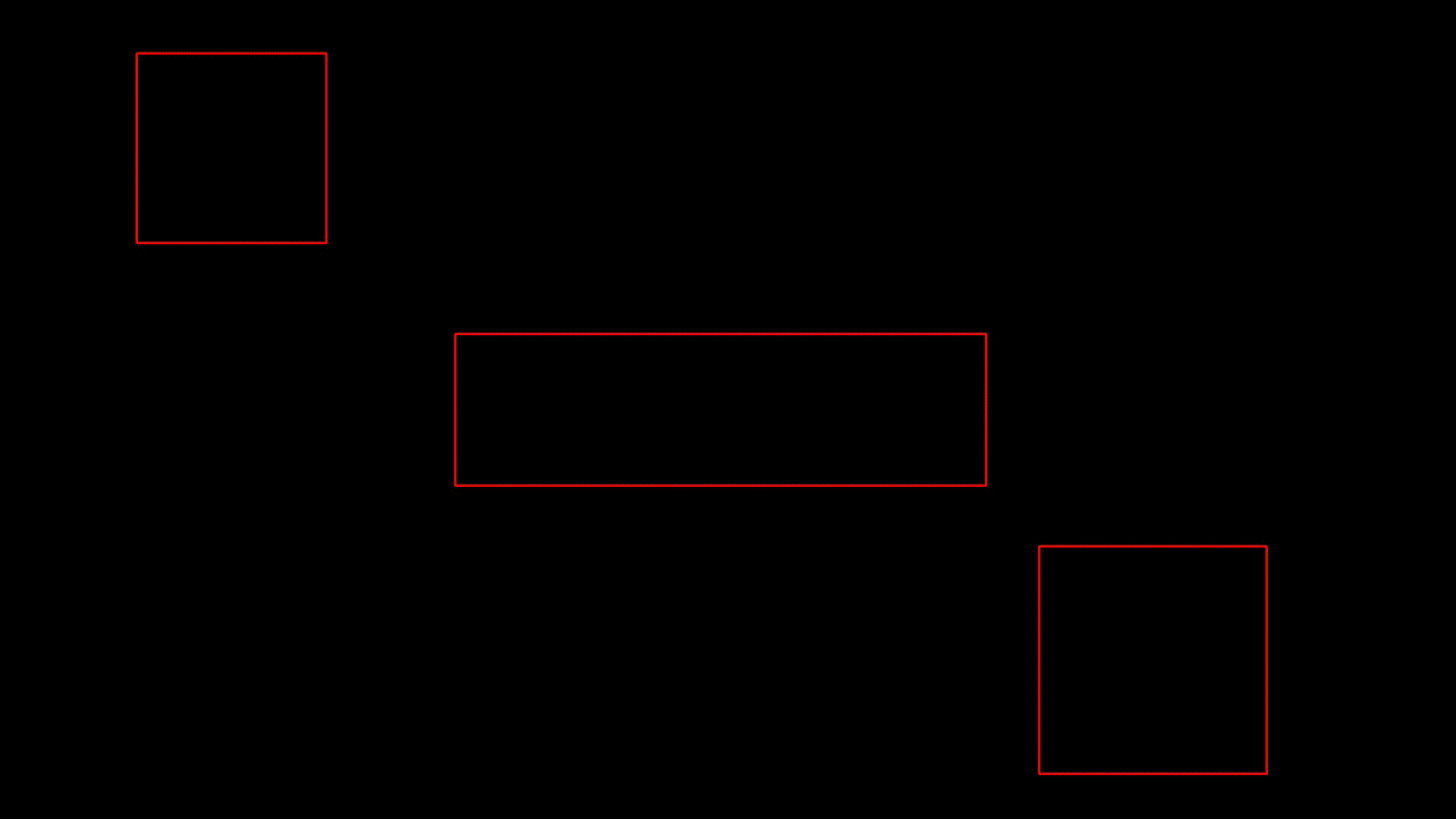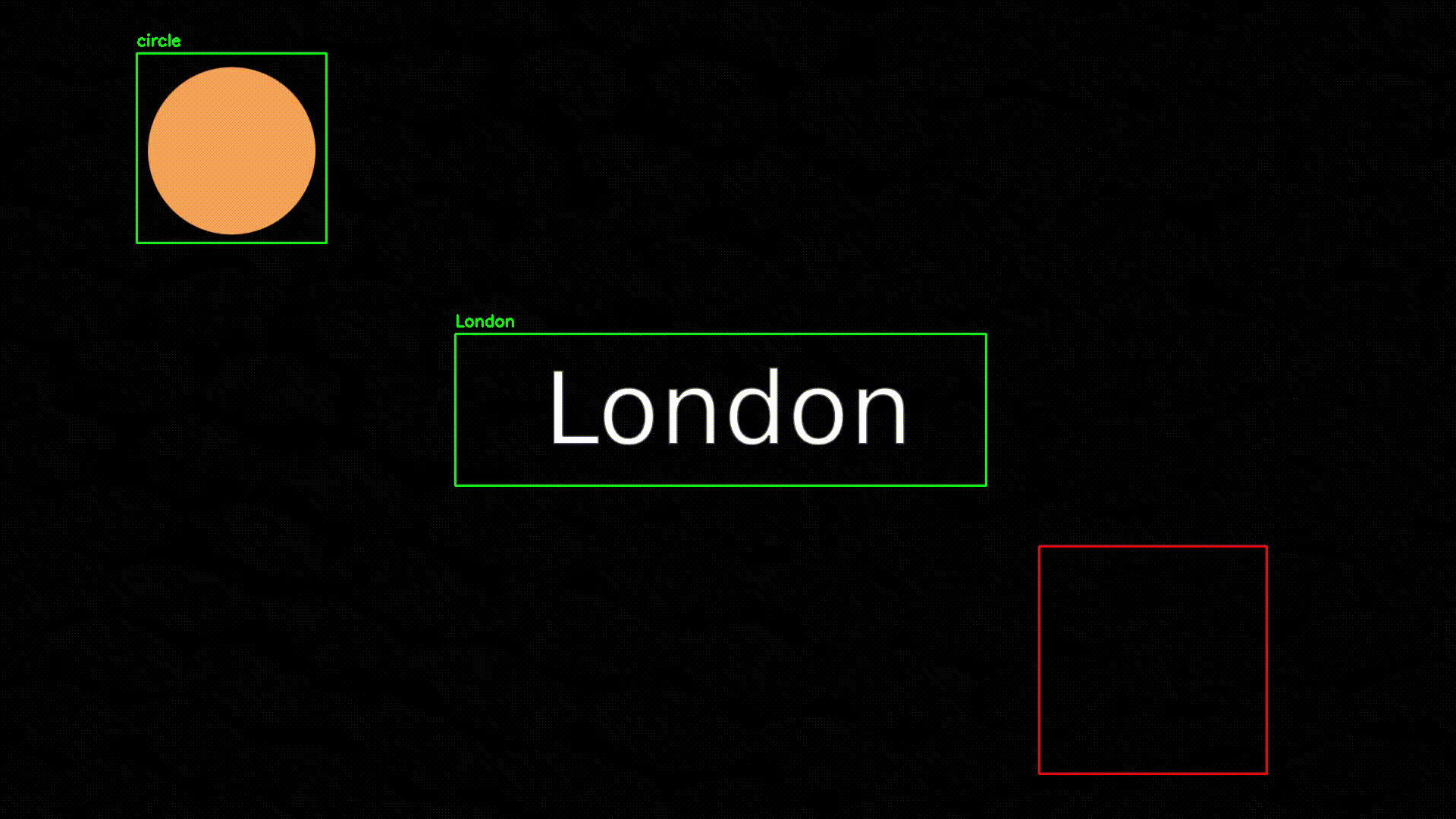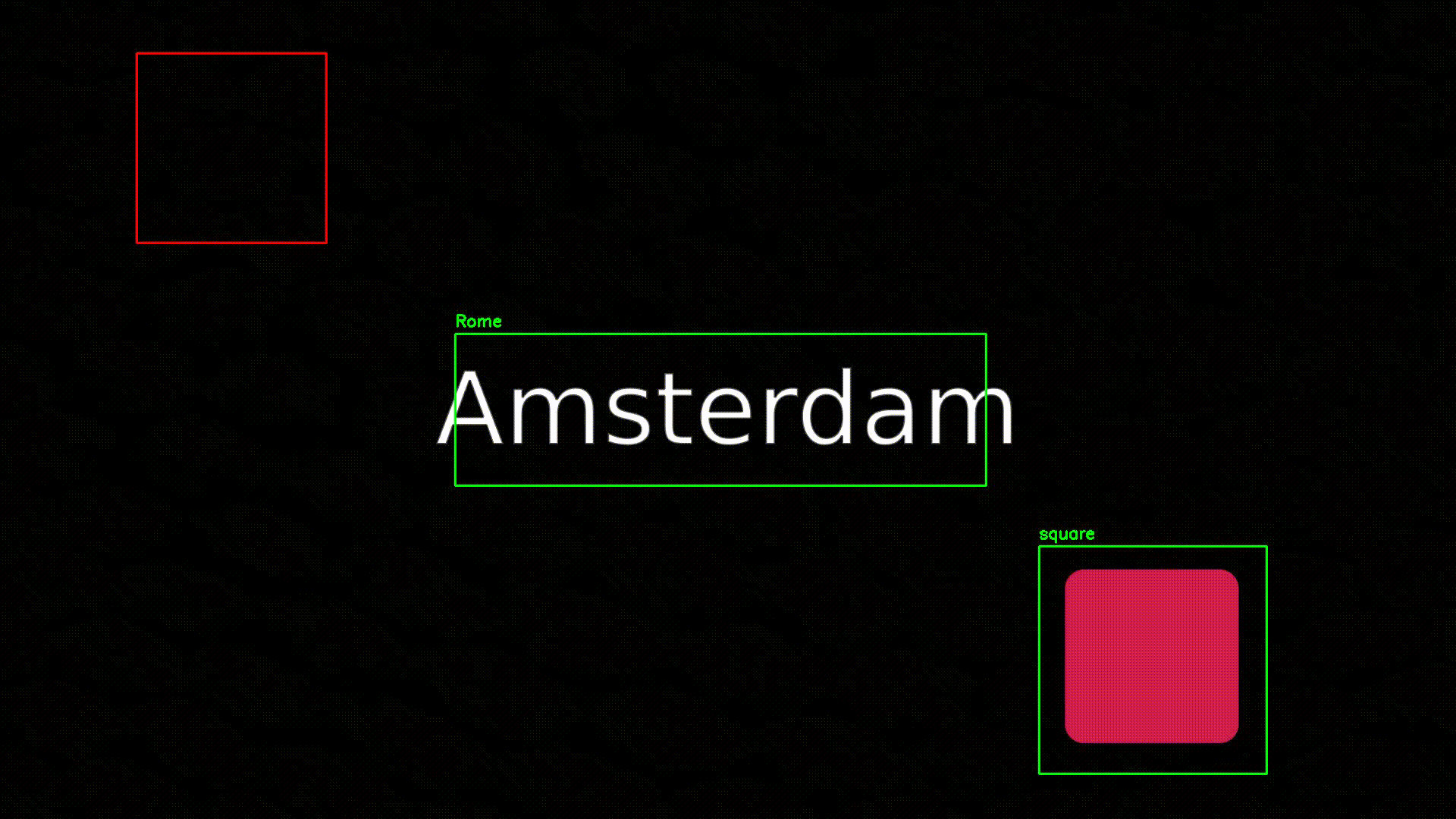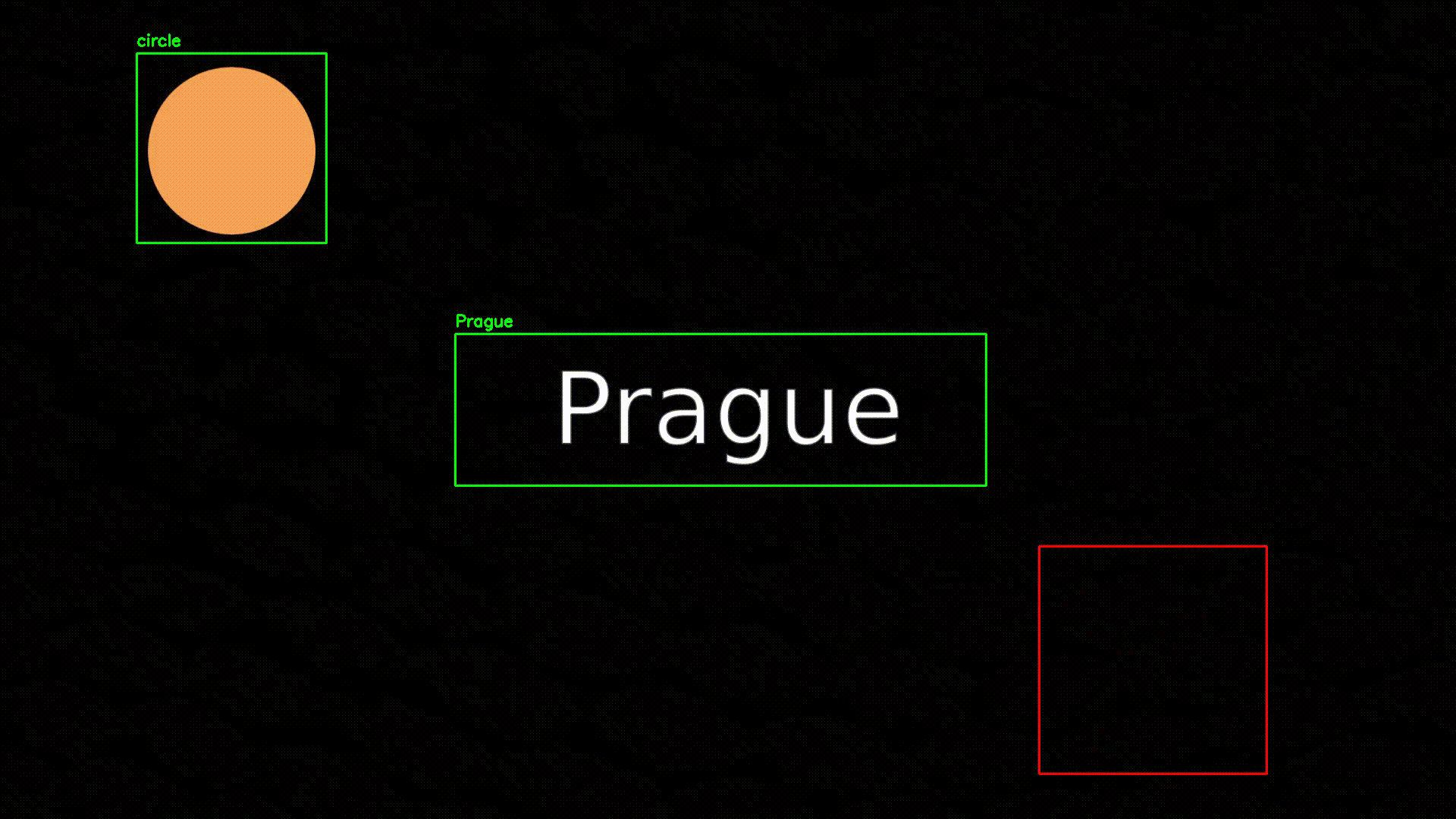
Pour suivre l'évolution des données sur une vidéo, nous allons dans un premier temps devoir préciser les coordonnées de la vidéo à analyser.
L'objectif est de fournir en entrée une liste de coordonnées à analyser sur la vidéo pour d'obtenir en sortie la liste des textes correspondants.
Voici à quoi ressemblerai le fichier JSON des coordonnées à analyser (ici seul le centre nous intéresse) :
[
{
"label": "center",
"box": [600, 440, 700, 200]
}
]
Et voici à quoi ressemblerai le fichier JSON de sortie :
[
{
"id": 1,
"time": 0.05081796646118164,
"data": {
"center": []
}
},
{
"id": 2,
"time": 0.9220726490020752,
"data": {
"center": ["Paris"]
}
},
{
"id": 3,
"time": 1.4295103549957275,
"data": {
"center": ["London"]
}
},
{
"id": 4,
"time": 1.7038054466247559,
"data": {
"center": ["London"]
}
},
{
"id": 5,
"time": 1.9825584888458252,
"data": {
"center": ["Rome"]
}
},
{
"id": 6,
"time": 2.276698589324951,
"data": {
"center": ["Amsterdan"]
}
},
{
"id": 7,
"time": 2.5571682453155518,
"data": {
"center": ["Prague"]
}
}
]
Extraire l'information d'une image
Avant toute chose, il est nécessaire d'initialiser un reader permettant d'extraire les informations textuels depuis une image.
import easyocr
reader = easyocr.Reader(['en'])
Nous pourrons ensuite extraire les informations du fichier JSON :
import json
# input json
input_json = 'path/to/input/data.json'
# coordinates
with open(input_json, 'r') as f:
coordinates = json.load(f)
Et récupérer les données de l'image sous la forme d'une tableau numpy
import PIL
import numpy as np
# input image
input_image = 'path/to/input/image.png'
# open image
img = PIL.Image.open(input_image)
# convert to numpy array
image_array = np.array(img)
Nous pourrons ensuite extraire les données de l'image grâce à la fonction readtext du reader de EasyOCR :
# initialize data
data = {}
for coordinate in coordinates:
# get subimage
cropped = image_array[y:y+h, x:x+w]
# get label and box
label = coordinate.get('label')
x, y, w, h = coordinate.get('box')
# update data
data[label] = reader.readtext(cropped, detail=0)
La variable data contient ici les données sous forme de texte d'une image pour chaque coordonée du fichier JSON fournit en entrée.
Extraire l'information d'une vidéo
Une vidéo est constituée d'une suite d'images. Pour analyser une vidéo, il nous suffira donc de boucler la logique expliquée précedemment.
Déplaçons donc la logique dans une foncton pour permettre sa réutilisation :
# Extract texts from image
def extract_information_from_image(reader, image_array, coordinates):
# initialize data
data = {}
for coordinate in coordinates:
# get subimage
cropped = image_array[y:y+h, x:x+w]
# get label and box
label = coordinate.get('label')
x, y, w, h = coordinate.get('box')
# update data
data[label] = reader.readtext(cropped, detail=0)
return data
Dans un premier temps, nous devons récupérer le fichier vidéo.
import cv2
# input video
input_video = 'path/to/input/video.mp4'
# open video
video = cv2.VideoCapture(input_video)
Nous pouvons ensuite utiliser une boucle while tant que la vidéo est ouverte.
Nous n'analyserons ici qu'une image sur 10 pour éviter de ralentir le programme.
# initialize counter
counter = 0
while video.isOpened():
# get the frame
_, frame = video.read()
# print extracted information
if counter % 10 == 0:
print(extract_information_from_image(reader, frame, coordinates))
# update counter
counter += 1
Cette logique peut être déplacée dans une fonction pour permettre sa réutilisation. De plus, il est pertinent d'ajouter des informations sur l'id de l'image et sur le temps où celle-ci apparaît dans la vidéo :
def get_data_from_video(path_to_video):
video = cv2.VideoCapture(path_to_video)
# initialize
data = []
counter = 0
initial_time = time.time()
id_image = 1
while video.isOpened():
_, frame = video.read()
# save extracted information
if counter % 10 == 0:
data.append({
"id": id_image,
"time": time.time() - initial_time,
"data": extract_information_from_image(reader, frame, coordinates)
})
id_image += 1
counter += 1
return data
Ecrire la sortie dans un fichier JSON
Pour permettre une exploitation future des données, nous pouvons les écrire dans un fichier JSON.
import json
import cv2
# paths
output_json = 'path/to/output/out.json'
input_video = 'path/to/input/video.mp4'
# get data
data = get_data_from_video(input_video)
# write data
with open(output_json, 'w') as f:
json.dump(data, f, indent=4)
Extraire l'information d'un stream
La logique d'extraction d'informations depuis un stream est similaire à celle depuis une vidéo. Cependant, nous devrons convertir chaque frame pour pouvoir les exploiter (cf Stack Overflow pour la solution).
def convert_frame_mss_to_cv2(frame):
# https://stackoverflow.com/a/51528497/18342998
frame = np.flip(frame[:, :, :3], 2)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
return frame
Le programme utilisant l'écran actif de l'utilisateur, il sera aussi nécessaire de prévoir un moyen de stopper la boucle infinie pour retourner les données.
Nous utiliserons ici la combinaison CTRL + C (KeyboardInterrupt en python).
from screeninfo import get_monitors
from mss import mss
def get_data_from_stream():
screen = get_monitors()[0]
width = screen.width
height = screen.height
sct = mss()
# initialize
data = []
counter = 0
initial_time = time.time()
id_image = 1
while True:
try:
# get the full screen
box = {'top': 0, 'left': 0, 'width': width, 'height': height}
frame = np.array(sct.grab(box))
frame = convert_frame_mss_to_cv2(frame)
# save extracted information
if counter % 10 == 0:
data.append({
"id": id_image,
"time": time.time() - initial_time,
"data": extract_information_from_image(reader, frame, coordinates)
})
id_image += 1
counter += 1
except KeyboardInterrupt:
break
return data
Il devient donc possible d'extraire les informations depuis une image, une vidéo ou un stream.
Conclusion
Nous avons vu ici comment extraire des informations depuis une vidéo ou un stream vidéo grâce à l'utilisation de EasyOCR et de OpenCV.
Pour aller plus loin, VOCR implémente cette logique ainsi que certaines fonctions supplémentaires comme la reconnaissance de patterns simples.